Neuromorphic Computing at Tennessee - Research Overview
Moore's Law is Dead.
In other words, the days of computer speeds doubling every 18 months are long over. For that reason, researchers are looking for alternatives to making conventional microprocessors fast. At Tennessee, we are part of this wave, and our approach is to look to the human brain for inspiration.
Our research agenda is ambitious:
Our goal is to design computing systems using principles from the brain. Instead of CPU's that execute instructions, our computing components are neurons and synapses that accumulate and transmit electrical charge. We compose the neurons and synapses into networks that solve various computational tasks. Unlike CPU's and conventional computer memory systems, neurons and synapses are simple, and enable our networks to be implemented with high speed and low power.
Our approach to research is vertical, encompassing the gamut of technologies required to explore this exciting area. These include:
- Models for neurons and synapses, and their composition into computing systems.
- Programming methodologies for these computing systems.
- Software simulation of these systems, leveraging parallel computing and GPU's.
- Conventional hardware implementation of these sytems (e.g. FPGA's, VLSI).
- Emergent hardware implementation of these systems (e.g. memristive and analog devices).
- System software support of simulators and hardware implementations.
- Application development.
Dynamic -- not Deep -- Learning
In the lingo of Machine Learning, our models are spiking neural networks, which pertain to neurons accumulating charge and firing over periods of time. This is as opposed to traditional neural networks, which are static organizations of mathematic formulas. In addition to their spiking behavior, our models are dynamic, which means that their structures can change over time. For examples, neurons and synapses may be created or destroyed over time, or their behaviors may change.
We "program" these systems by training them, allowing them to learn. We call this approach dynamic learning, because of the dynamic nature of our systems. This is as opposed to the currently popular deep learning systems, which are built on traditional, non-spiking neural networks. Deep learning systems have been highly successful in the areas of image classification and customer preference determination. They are not designed for applications that are time-dependent or dynamic, which is where we are focused.
We view dynamic and deep learning as complementary technologies. For example, an airplane navigation system may employ deep learning to "recognize" features in its surroundings. Dynamic learning may then be employed to make real-time navigational decisions based on these features, and how they change over time.
Taken together, we believe that the two types of learning will enable complex and powerful computing technologies in the future.
Three Dynamic Computing Models
Our research is focused on three dynamic computing models summarized below:
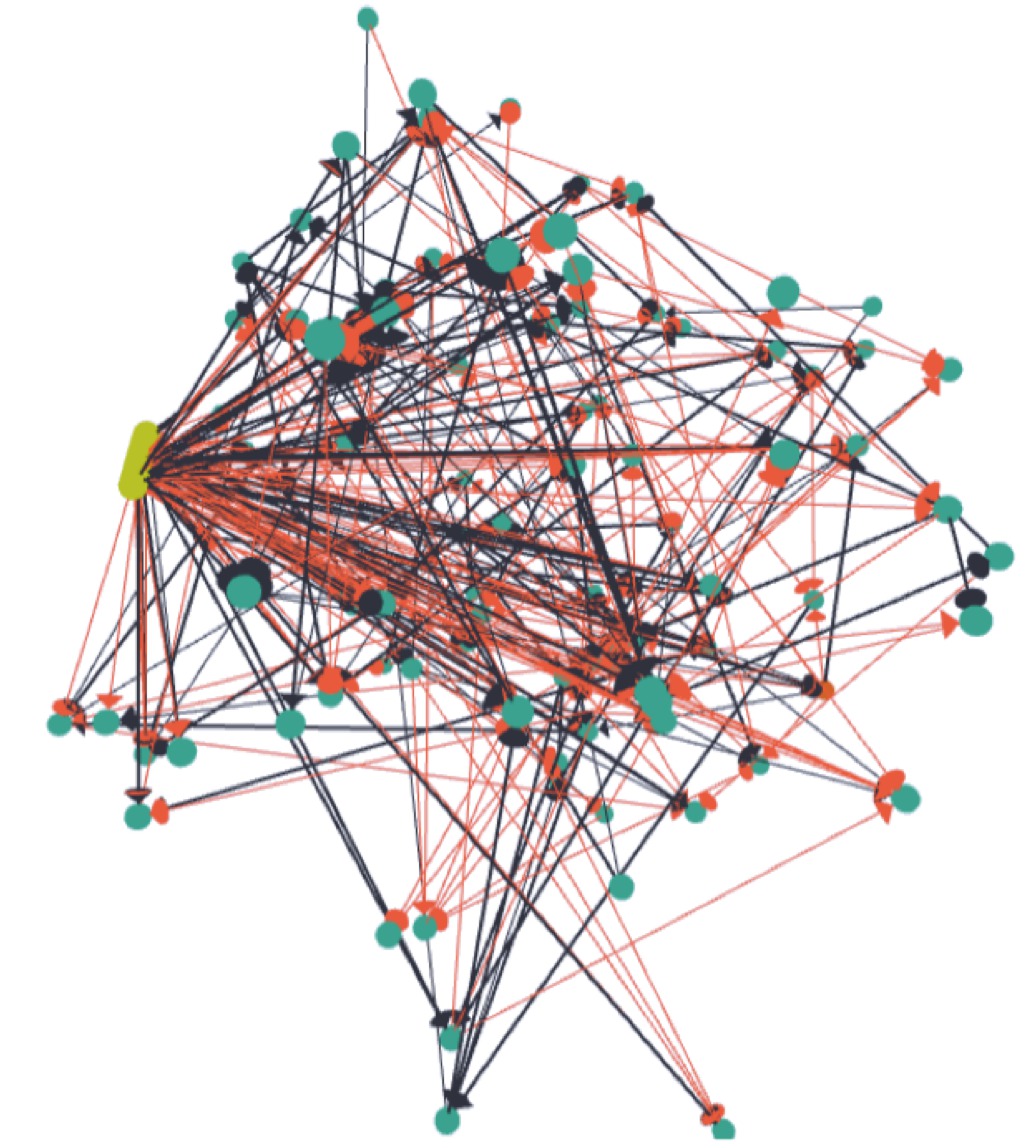 NIDA: Neuroscience-Inspired Dynamic Architecture Neurons and synapses laid out in 3D space. Synaptic delays based on distance. Implemented in software. | 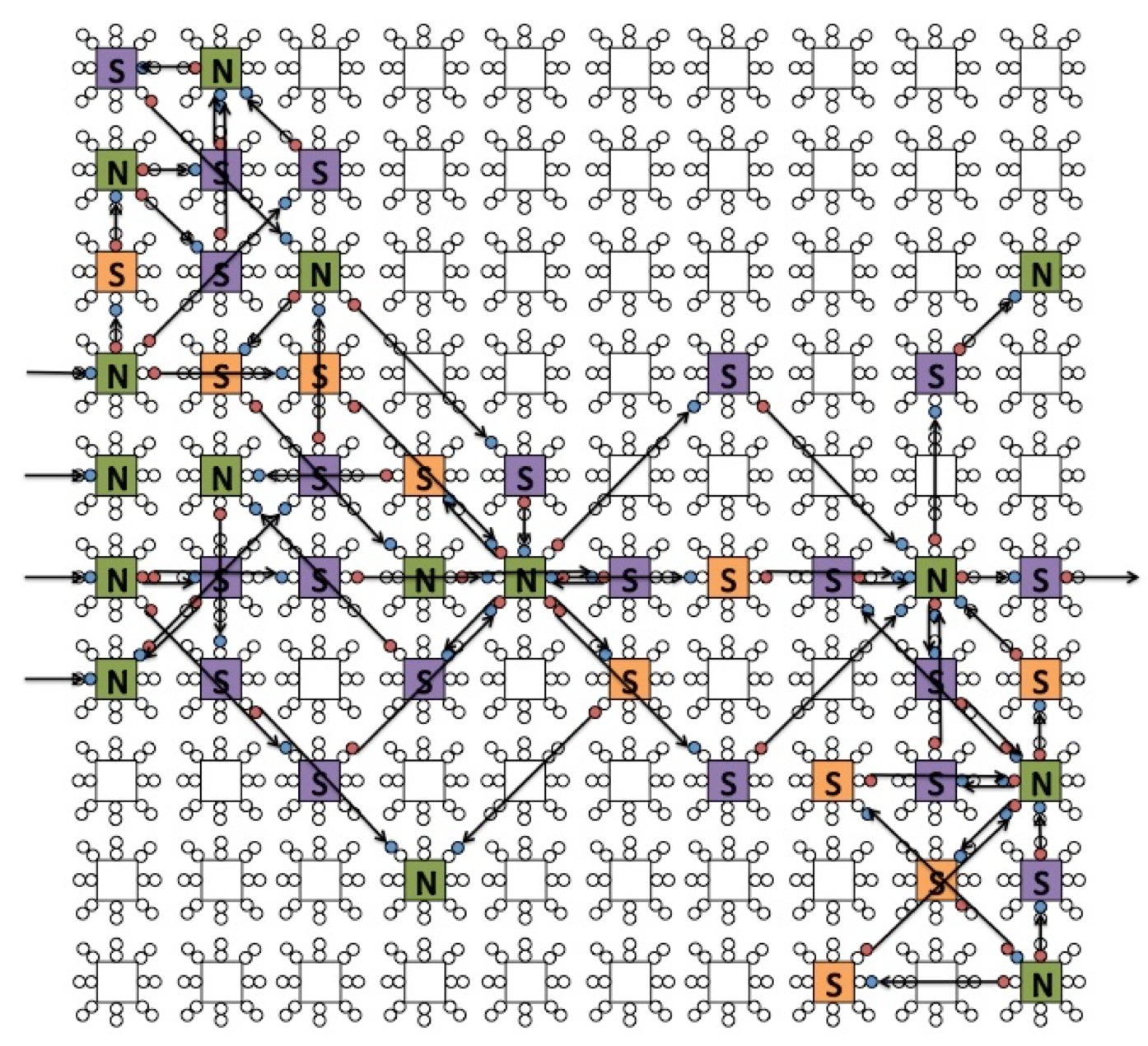 DANNA: Dynamic Adaptive Neural Network Arrays Two-dimensional grid of elements. Elements can be neurons or synapses. 16 nearest neighbor connectivity. Programmable synaptic delays. FPGA implementation deployed. VLSI implementation designed. | 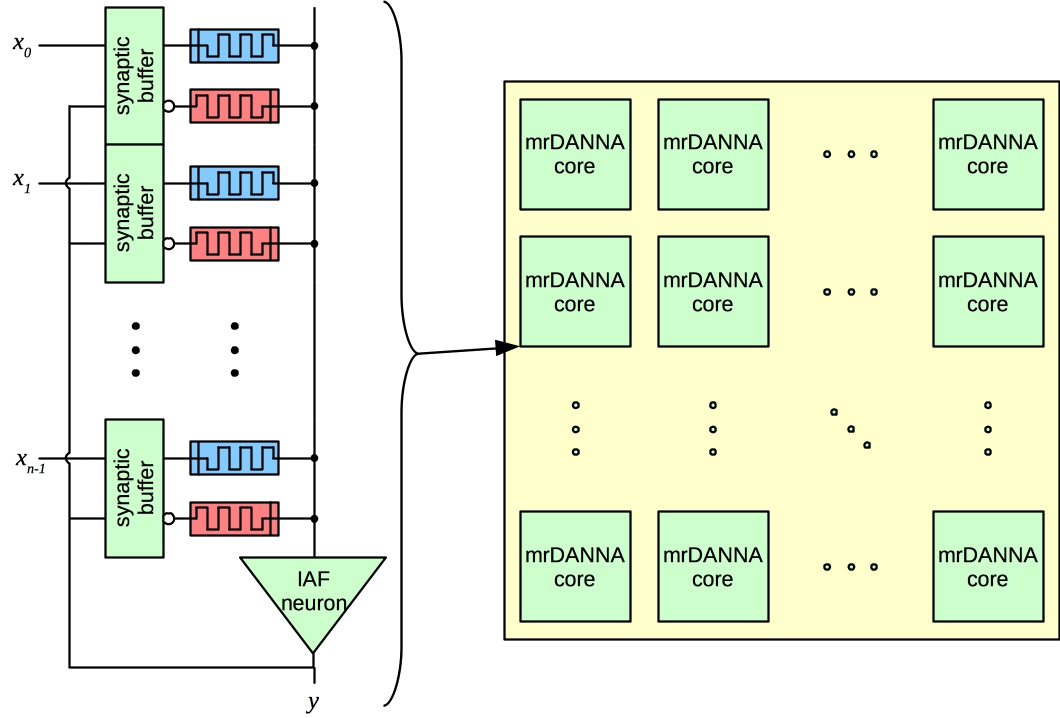 mrDANNA: Memristive Dynamic Adaptive Neural Network Arrays Leverages analog memristive hardware. More flexible connectivity and delays. Still under development. |
In each model, the computing device receives input as charge events to certain neurons. These charge events can vary in magnitude and occur over time. An application of the device must convert its input into charge events that it applies to the device.
Certain synapses are designated to be output synapses. Their firing denotes output from the device. Their magnitude and timing must be interpreted by an application in a manner that is useful to the application.
A concrete example: Inverted Pendulum on a Cart
This is a classic application from control theory (for example, see the description on Wikipedia. A pole is to be balanced on a cart that can move horizontally within a fixed area. The pole has a mass on its top. The pole starts in some imbalanced starting state, at some angle from vertical, rising or falling at some velocity. The goal of the system is to apply periodic forces to move the cart left or right, to keep the pole from falling, and to keep the cart from moving beyond its boundaries.
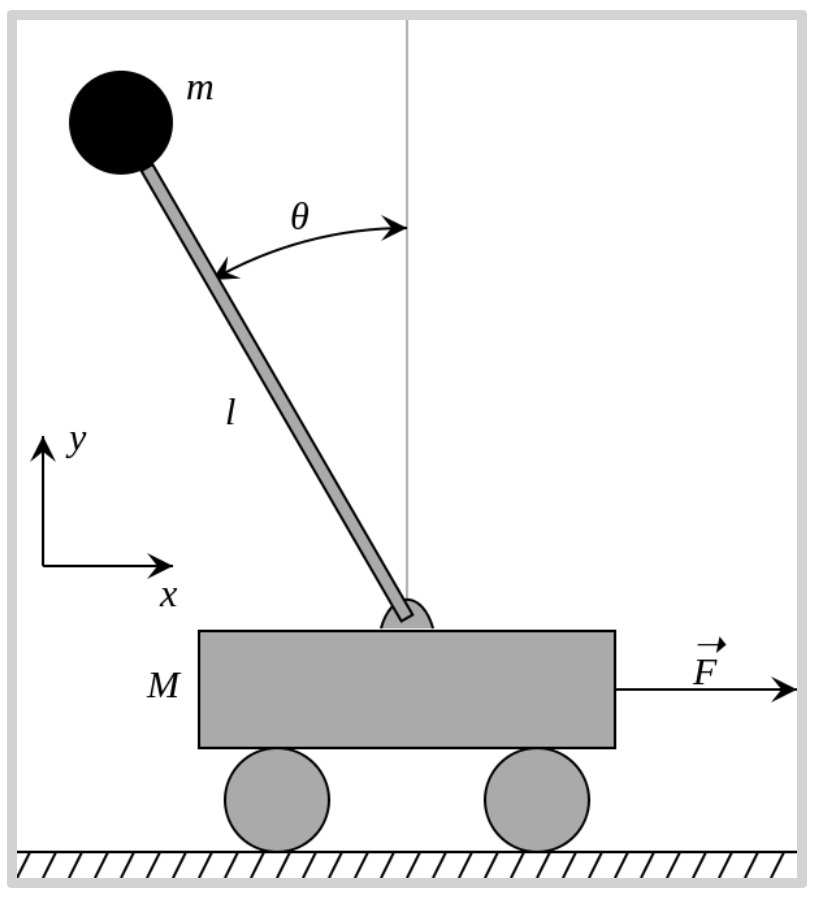 Inverted Pendulum on a Cart. |
To apply one of our models to this problem, we need to take an instance of the inverted pendulum problem and map it to input pulses. We need to map the output pulses of our model to cart movements. If our model is programmed correctly, it will keep the pole balanced without having the cart go beyond its fixed boundaries.
We show a concrete example in the figure below.
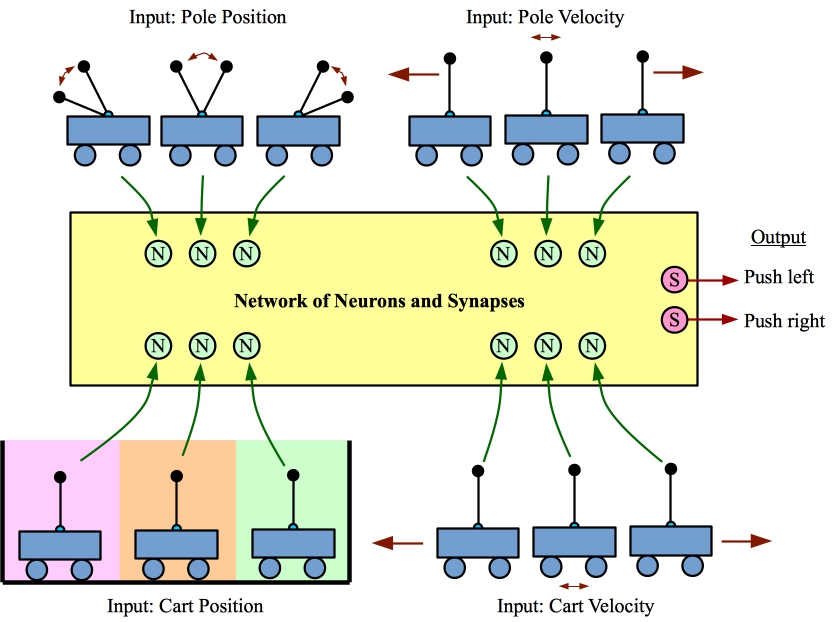
Example of turning an instance of the Inverted Pendulum on a Cart into input and output that our networks can understand.
We sample the state of the system at regular intervals, like 1/50 of a second. At that point we represent the state of the system with four parameters:
- Position of the pole, which we translate into one of three values: Left, center and right.
- Velocity of the pole, which we translate into one of three values: Moving left, stable and moving right.
- Position of the cart, which we translate into one of three values: Left, center and right.
- Velocity of the cart, which we translate into one of three values: Moving left, stable and moving right.
We turn each of these parameters into a single pulse to a dedicated input neuron. For example, if the pole is on the left, we would send a single pulse to an input neuron that corresponds to that state.
We let the network execute for a certain amount of time, and we measure output pulses on two synapses, one that corresponds to "push cart left", and one that corresponds to "push cart right." Whichever of these has more output pulses determines how we push the cart.
We then wait the proper time (1/50 of a second) before repeating the process. If the network is programmed correctly, the pole stays balanced.
We have developed networks for both the NIDA and DANNA models that solve the Inverted Pendulum on a Cart problem in just this manner. For further information, please see the Research Demos.
Programming Via Evolutionary Optimization
For a given model, a programmed network is a collection of neurons with specified firing thresholds and refractory periods, plus a collection of synapses between neurons. Depending on the model, the time that it takes charge to travel along a synapse is either a function of the locations of its incident neurons (NIDA), or is a programmable parameter (DANNA).
Our current methodology for programming is one that employs evolutionary optimization. The input neurons and output synapses are affixed a priori, and then a population of randomly programmed networks is generated. For a given application, a set of training instances are executed on each network in the population, and the success of each network is quantified by a fitness function. The best networks are then chosen from the population, and used to generate the next population via mutation and crossover operations. One pass of evolutionary optimization is called an epoch.
Because our models are dynamic, every component in our models is programmable via evoluationary optimization. This includes neuron and synapse placement, which differentiates our approach from approaches that affix network structure, and only change parameters of neurons and synapses.
As we explore applications of this approach, our intent is to identify network sub-structures that span applications, so that we may use them as building blocks in evolutionary optimization. This will allow us to program larger networks without facing state space blow-up.
FPGA Implementation of DANNA
For the DANNA model, we have implemented the model on the Xilinx Virtex-7 XC7V690T (supporting DANNA arrays up to 47 X 47), and XC7V2000T (supporting arrays up to 75 X 75). We have verified the functionality of these implementations with a cycle-level simulator. Please see the 2016 IJCNN Paper, "An Application Development Platform for Neuromorphic Computing" for more information.
Example applications
The following are applications that are in our current area of focus. We are always looking for more applications, and are very willing to partner with others on application exploration. Please contact James Plank if you are interested in exploring your application with our models.
- Inverted Pendulum on a Cart: See above for a description. We have networks in both NIDA and DANNA that keep the pendulum balanced.
- Flappy Bird: This is another control application with a very simple structure that maps well to our dynamic learning approach. It is based on the popular cell phone game Flappy Bird. We will have further description of this application on our demonstration page.
- Data Classification: In this application, we employ data sets from the UCI Machine Learning Repository. A data sets is composed of instances. Each instance has values for various parameters, plus a classification. A canonical example is the "Iris" data set, which contains 50 instances of each of three types of Iris flower. Each instance measures four parameters of the flower, and classifies the instance as "Iris Setosa," "Iris Virginica" or "Iris Versacolour." We train our networks on a subset of the data set, and then rate its fitness on how successfully it classifies the entirety of the data set. For a more complete discussion of our experimental work on this type of classification in both NIDA and DANNA, please see our 2016 IJCNN paper on our evolutionary optimization framework.
- Handwritten Digit Classification: This is another classification problem. Here, the challenge is to recognize hand-written digits from the well-known MNIST database. Image classification is a problem that is in the wheelhouse of Deep Learning systems, which achieve classification error rates under 1 percent. We don't expect our systems to outperform Deep Learning on this application, but we have trained NIDA networks that achieve less than 10 percent classification error, and DANNA networks that achieve less than 20 percent.
- Spoken Language Recognition: We have assembled 200 five-second audio clips of spoken languages. These are partitioned into English, Arabic, Russian and Korean. We are currently working on training NIDA and DANNA networks to recognize clips as belonging to each of the four languages.
- Anomaly Detection in Packet Rates: The goal of this application is to monitor the interarrival rate of packets arriving at an internet site to detect when this rate changes. This application leverages the temporal nature of our models, as the inputs are simply pulses that occur when a packet arrives. Please see the 2014 BICA paper for more information.